| Exam Name: | Databricks Certified Associate Developer for Apache Spark 3.5 – Python | ||
| Exam Code: | Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Dumps | ||
| Vendor: | Databricks | Certification: | Databricks Certification |
| Questions: | 136 Q&A's | Shared By: | ahad |
44 of 55.
A data engineer is working on a real-time analytics pipeline using Spark Structured Streaming.
They want the system to process incoming data in micro-batches at a fixed interval of 5 seconds.
Which code snippet fulfills this requirement?
3 of 55. A data engineer observes that the upstream streaming source feeds the event table frequently and sends duplicate records. Upon analyzing the current production table, the data engineer found that the time difference in the event_timestamp column of the duplicate records is, at most, 30 minutes.
To remove the duplicates, the engineer adds the code:
df = df.withWatermark("event_timestamp", "30 minutes")
What is the result?
A data engineer is working on the DataFrame:
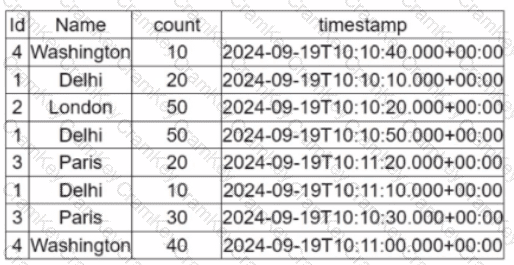
(Referring to the table image: it has columns Id, Name, count, and timestamp.)
Which code fragment should the engineer use to extract the unique values in the Name column into an alphabetically ordered list?
A data scientist is working with a Spark DataFrame called customerDF that contains customer information. The DataFrame has a column named email with customer email addresses. The data scientist needs to split this column into username and domain parts.
Which code snippet splits the email column into username and domain columns?

TESTED 31 Jul 2026