Databricks Certified Associate Developer for Apache Spark 3.5 – Python
Last Update Jul 30, 2026
Total Questions : 136
To help you prepare for the Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Databricks exam, we are offering free Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Databricks exam questions. All you need to do is sign up, provide your details, and prepare with the free Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 practice questions. Once you have done that, you will have access to the entire pool of Databricks Certified Associate Developer for Apache Spark 3.5 – Python Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 test questions which will help you better prepare for the exam. Additionally, you can also find a range of Databricks Certified Associate Developer for Apache Spark 3.5 – Python resources online to help you better understand the topics covered on the exam, such as Databricks Certified Associate Developer for Apache Spark 3.5 – Python Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 video tutorials, blogs, study guides, and more. Additionally, you can also practice with realistic Databricks Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 exam simulations and get feedback on your progress. Finally, you can also share your progress with friends and family and get encouragement and support from them.
3 of 55. A data engineer observes that the upstream streaming source feeds the event table frequently and sends duplicate records. Upon analyzing the current production table, the data engineer found that the time difference in the event_timestamp column of the duplicate records is, at most, 30 minutes.
To remove the duplicates, the engineer adds the code:
df = df.withWatermark("event_timestamp", "30 minutes")
What is the result?
A data scientist is working with a Spark DataFrame called customerDF that contains customer information. The DataFrame has a column named email with customer email addresses. The data scientist needs to split this column into username and domain parts.
Which code snippet splits the email column into username and domain columns?
A data engineer is working on the DataFrame:
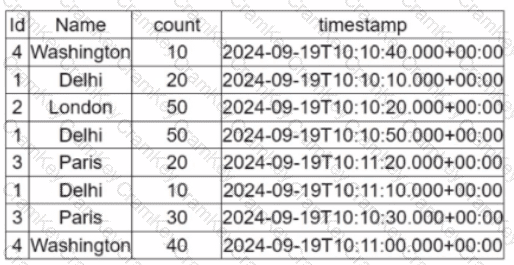
(Referring to the table image: it has columns Id, Name, count, and timestamp.)
Which code fragment should the engineer use to extract the unique values in the Name column into an alphabetically ordered list?
A data engineer wants to process a streaming DataFrame that receives sensor readings every second with columns sensor_id, temperature, and timestamp. The engineer needs to calculate the average temperature for each sensor over the last 5 minutes while the data is streaming.
Which code implementation achieves the requirement?
Options from the images provided:
A)
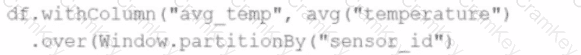
B)

C)

D)


TESTED 30 Jul 2026